
Start a Chat with Us!



The chat is obligation-free — just share your ideas and goals
A Unified Visual Style for Social Media, Websites, Applications, and Presentations
Save Time and Budget on Design by 4−10x
Delivering unique and recognizable branding for your business, even for urgent tasks. Suitable for businesses of any size.
Delivering unique and recognizable branding for your business, even for urgent tasks. Suitable for businesses of any size.

Your Personal AI Illustrator:
Professional Branding Made Effortless!
Professional Branding Made Effortless!
Create Stunning Visuals Like Top Brands in Minutes!

Faster and more cost-effective than any traditional agency
Unique AI illustrations tailored for your business, accelerating the work of marketers and designers while boosting brand recognition.
Now available for businesses of any size.
Now available for businesses of any size.
AI Branding
-
 Speed of DeliveryCreate visuals in minutes instead of hours. Save time on coordination and decision-making.
Speed of DeliveryCreate visuals in minutes instead of hours. Save time on coordination and decision-making. -
 Brand ConsistencyA unified style across all materials.
Brand ConsistencyA unified style across all materials.
Eliminates design variations that could "break" your brand identity. -
 Recognizability and FlexibilityAny task is solved instantly: from landing page graphics to festive campaign visuals.
Recognizability and FlexibilityAny task is solved instantly: from landing page graphics to festive campaign visuals.
From Christmas trees to branded characters—everything in a unique style. -
 Cost Efficiency in DesignNo need to maintain an in-house team of illustrators for urgent tasks.
Cost Efficiency in DesignNo need to maintain an in-house team of illustrators for urgent tasks.
Lower production costs without compromising quality. -
 Support for Any TaskVisuals for social media, apps, and presentations.
Support for Any TaskVisuals for social media, apps, and presentations.
Even complex tasks like photorealistic objects are handled seamlessly. -
 VersatilitySuitable for both designers and marketers.
VersatilitySuitable for both designers and marketers.
A solution for large companies and startups alike.
Set tasks and get instant results.
The model operates on a free service, requiring no design or prompt engineering skills.
The model operates on a free service, requiring no design or prompt engineering skills.
How to Work with the AI Illustrator?




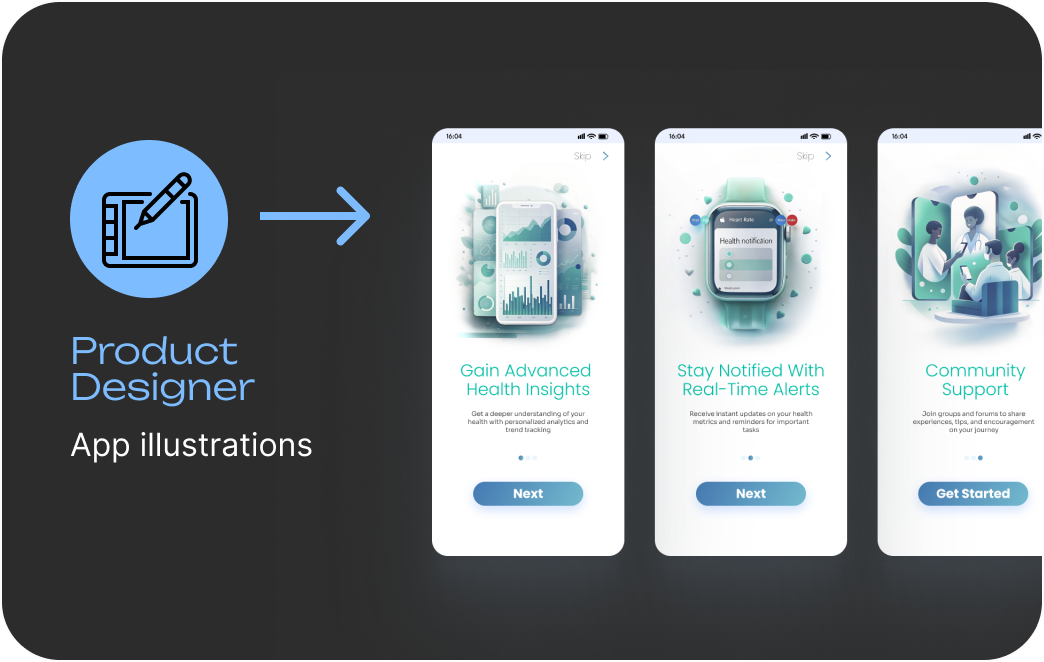
These are just a few examples of possible applications.
Accelerates designers, useful even for businesses.
Accelerates designers, useful even for businesses.
Any format and style
Tailored to meet your business and branding needs: from vector art to photorealism
Branded characters — created with a single click, no 3D required.
Available in any angle or pose.
Available in any angle or pose.
Консистентные персонажи




Your branded character can be anything: animated, cartoonish, or photorealistic, while remaining consistent
Any level
of realism
of realism




Create any illustrations, including vector graphics
Need vector art?
You can create this with a single click in a unique brand style:
from Santa Claus for Christmas to Halloween decorations
from Santa Claus for Christmas to Halloween decorations




Graphics for holidays and events

No need for ChatGPT to craft prompts.
Just describe what you need
One to two words is enough
Just describe what you need
One to two words is enough
Just
describe it
describe it




Expert consultation
Helping identify your needs in illustrations and find the most optimal formats
What will you get after placing an order?

Development of a unique style
Custom illustrations tailored to your brand, enhancing its recognizability

Up to 10 visuals and 2 trained AI models
For creating graphics in your brand’s unique style

Training to work with AI graphics
Your team will master interaction with AI illustrator in just 5 minutes
5
you need an AI illustrator
reasons why

01
Free limits
Connect the model to services offering 20–50 free images daily for each account. This minimizes costs even for large teams

02
No hidden fees
Creating a single image takes just 2–3 minutes, saving your resources and avoiding unexpected expenses

03
Speed and optimization
Save time and money by creating custom graphics in your brand’s style in just minutes without sacrificing quality

04
Cost efficiency for small teams
Achieve the quality of major brands without incurring excessive expenses by optimizing your creative processes
05
Consistency for large brands
Maintain a unified style across all materials without interruptions, ensuring brand cohesion and a professional image
We work efficiently, but be ready to actively participate in the process
How do we create an AI illustrator for you in just 3 days?





At steps 1–3, your active participation will be required
Illustrators:
Who to choose?
In-house VS Outsourced VS AI
Illustrators
In-house
Outsourced
AI (our service)
Required level
Middle/High-level
(+ Art Director)
(+ Art Director)
High-level
(+ Art Director)
(+ Art Director)
High-level
(created under C-level design director supervision)
(created under C-level design director supervision)
Time to create style
1–3 months
research, test iterations + guidelines
research, test iterations + guidelines
1−4 months
complicated due to remote collaboration
complicated due to remote collaboration
3 days
style setup + 10 illustrations
style setup + 10 illustrations
Time to create one illustration
~4 hours
~2 illustrations per day
~2 illustrations per day
~4–8 hours
~1–2 illustrations per day
~1–2 illustrations per day
1 −30 minutes
(generation + refinement if needed)
(generation + refinement if needed)
Consistency
Hight
depends on illustrator’s level and art director’s control
depends on illustrator’s level and art director’s control
Medium
high risk of inconsistency due to remote work
high risk of inconsistency due to remote work
Full
style secured in the AI model, all illustrations identica
style secured in the AI model, all illustrations identica
Risks
Hiring, burnout, human factor
Long approvals, missed deadlines, difficulty in maintaining a unified style
Minimal
dependent on tuned model and service availability
dependent on tuned model and service availability



By the way, all our illustrations are also created using AI models without manual editing
The advantages are clear
Visuals are an essential part of branding. With the AI Illustrator, this process becomes even more accessible
We Made the Graphics Creation Process Affordable
Illustrators
In-House
Outsourced
AI (Our Service)
Scalability & Productivity
Limited
to 20–40 illustrations per month
to 20–40 illustrations per month
Limited
by contractor availability
by contractor availability
Unlimited
up to 50+ illustrations per day
up to 50+ illustrations per day
Cost of Style Creation
$4,000–$15,000
includes salaries of illustrators and art directors
includes salaries of illustrators and art directors
$2,000–$20,000
depending on freelancer/studio rates
depending on freelancer/studio rates
$1,800
(basic package),
$500 (special offer)
(basic package),
$500 (special offer)
Cost per Illustration in Style
~ $100–$300
depending on iterations and role of art director
depending on iterations and role of art director
~ $50–$500
freelancer/studio pricing
freelancer/studio pricing
$0
(+ designer’s time for complex request)
(+ designer’s time for complex request)


Get more than just illustrations—gain a system that optimizes creation and reduces dependency on human resources.
Invest in a system, not a process
FAQ
Got Questions?
1. We have extensive experience in training models for consistent graphics since 2022.
2. The quality is overseen by a high-level design director.
3. We provide training materials to ensure your team can consistently achieve excellent results.
4. In the hands of designers, the graphics created with AI will be indistinguishable from human illustrators’ work. And better yet—no risk of “misunderstood briefs.”
2. The quality is overseen by a high-level design director.
3. We provide training materials to ensure your team can consistently achieve excellent results.
4. In the hands of designers, the graphics created with AI will be indistinguishable from human illustrators’ work. And better yet—no risk of “misunderstood briefs.”
Because the process is automated, we provide not just illustrations, but a system that generates them for you.
Moreover, these are introductory prices under a special offer.
Moreover, these are introductory prices under a special offer.
Our model is easily adaptable to new requirements or tasks.
The cost of retraining starts at 20% of the initial price and won’t exceed the base cost. We will lock in the price for all future updates.
For example, if you ordered a model under the special offer and need to expand the dataset in a few months with all the generated materials, this might cost you as little as $100
The cost of retraining starts at 20% of the initial price and won’t exceed the base cost. We will lock in the price for all future updates.
For example, if you ordered a model under the special offer and need to expand the dataset in a few months with all the generated materials, this might cost you as little as $100
Our technology is scalable, and we offer solutions for any volume of work.
If you need more than 50 illustrations per day, we can provide a model connected to the service, with a single paid account for your designer at $10–20 per month.
Upon request, we can configure the system on your internal server. In this case, the integration cost will need to be discussed individually.
If you need more than 50 illustrations per day, we can provide a model connected to the service, with a single paid account for your designer at $10–20 per month.
Upon request, we can configure the system on your internal server. In this case, the integration cost will need to be discussed individually.
Yes, in this case, you provide the existing materials, and we will select those required for the dataset and prepare them for training. This won’t affect the cost.
Although it might require additional time on our end, we can skip the style approval step.
Although it might require additional time on our end, we can skip the style approval step.
This is the ideal scenario: we will train the model on your existing dataset, teach your illustrator to work with it, and they will achieve incredible speed without compromising quality or consistency.
We train the first model on created images or your dataset, then test it. It will respond to minimal prompts (even single words) to produce results as close as possible to the original dataset (input graphics used for training).
This model is usually sufficient for non-designers.
The second model is adapted for more flexible requests depending on the tasks, such as creating different styles (levels of realism, vector graphics, etc.). This model suits advanced users, including designers.
Both models can be combined. We will also provide detailed training materials specific to your case.
This set is sufficient to cover all your needs. If you realize that additional customization (e.g., a third model) is required, we can provide it as well.
This model is usually sufficient for non-designers.
The second model is adapted for more flexible requests depending on the tasks, such as creating different styles (levels of realism, vector graphics, etc.). This model suits advanced users, including designers.
Both models can be combined. We will also provide detailed training materials specific to your case.
This set is sufficient to cover all your needs. If you realize that additional customization (e.g., a third model) is required, we can provide it as well.
Basic Package:
«From Scratch»
Perfect for starting your brand
«From Scratch»
Perfect for starting your brand
- Duration: 3 days
Creation of a brand style
10 illustrations
2 trained AI models
Training materials for your team (AI brand guide)
$1,800
Order now
Advanced Package:
«Existing Graphics»
For process optimization
«Existing Graphics»
For process optimization
- Duration: 3 days
Transformation of your graphics into a dataset
2 trained AI models
- Training materials for your team (AI brand guide)
$1,800
Order now
Special:
«Review Deal»
Only 3 opportunities available
«Review Deal»
Only 3 opportunities available
- Duration: 3 days
Work in the format of the Basic or Advanced package
- In exchange for a review (Contact us for details)
$500
Discuss Options
Yes, that’s correct
The price remains the same
The creation of a new style includes the development of up to 10 options to choose from.
If you already have a style, we will need to review all your graphics to prepare the perfect training dataset for the model.
This process might even be more labor-intensive but eliminates the lengthy style approval phase, speeding up the process.
If you already have a style, we will need to review all your graphics to prepare the perfect training dataset for the model.
This process might even be more labor-intensive but eliminates the lengthy style approval phase, speeding up the process.
Get in Touch,
to learn more about how to get the special offer

Let’s discuss your project details!
By submitting the form, you agree to our Privacy Policy.
Let’s discuss your project details!
By submitting the form, you agree to our Privacy Policy.